Beating Claude Opus 4.5 at Kernel Generation with a 3B-Active RL Agent
A 30B MoE model with only 26.7M LoRA parameters generates faster NKI kernels than Claude Opus 4.5 — achieving 1.47x speedup and 94% fast rate on 250 benchmark tasks. The key: reward shaping that teaches the agent to pipeline operations across multiple compute engines on AWS Trainium hardware.
Why kernel generation for custom AI silicon is an open problem
Most LLM-based kernel generation research targets CUDA. NVIDIA GPUs dominate training data, so frontier models already know CUDA well. But custom AI accelerators like Trainium use fundamentally different programming models with minimal representation in pretraining corpora.
NeuronCores have four specialized compute engines — Tensor (matrix multiply), Vector (elementwise), Scalar (control flow), and GpSimd (transcendentals). Writing NKI kernels requires managing data across three memory levels (HBM, SBUF, PSUM), expressing computation as 2D tiles with a fixed 128-element partition dimension, and orchestrating work across all four engines simultaneously. Frontier LLMs struggle with this because they’ve seen very few NKI examples during pretraining.
We asked: can agentic reinforcement learning close this gap? Our approach builds on CUDA-Agent (Wu et al., 2026), which demonstrated that RL-trained agents can generate high-performance CUDA kernels, and adapts the idea to a fundamentally different hardware target.
Teaching an agent to write hardware-optimized kernels
NKI-Agent combines data synthesis, a multi-turn tool-using agent, and hardware-aware PPO training.
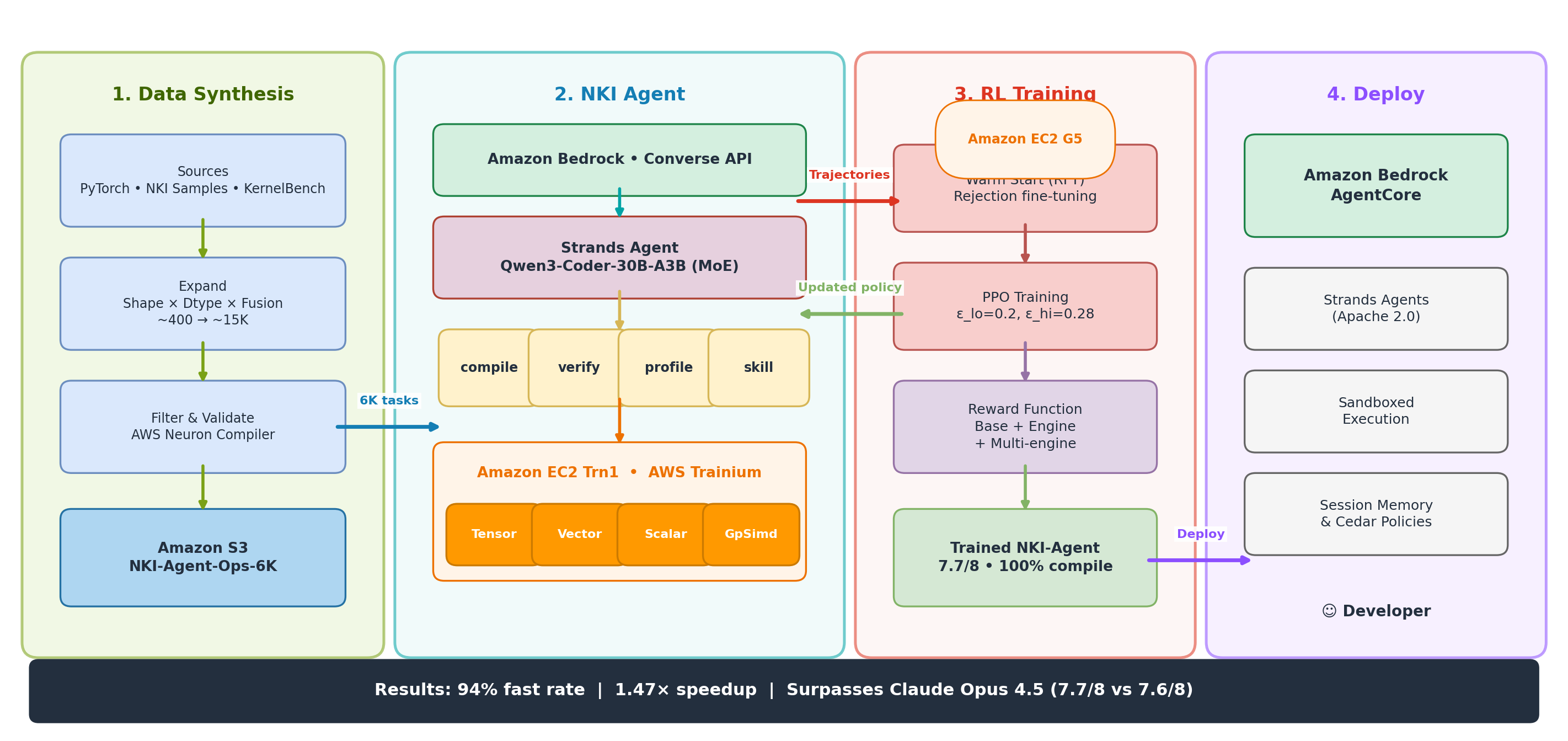
Synthesizing 6,000 training tasks for a data-scarce domain
No NKI kernel benchmark existed, so we built one. Following the task formulation from KernelBench (Ouyang et al., 2025), we started from ~400 seed operations from PyTorch, nki-samples, and KernelBench itself, then applied combinatorial expansion across shapes, dtypes (bf16, fp32, fp8), and fusion patterns to produce ~15,000 candidates. After filtering through the AWS Neuron compiler and runtime for correctness and timing stability, we kept 6,000 curated tasks.
Compile-verify-profile: a tight feedback loop
The agent, built on Strands Agents (Apache 2.0), follows a ReAct-style loop — similar to SWE-agent (Yang et al., 2024) and Toolformer (Schick et al., NeurIPS 2023) — with four tools: compile_kernel (compile NKI code, return errors), verify_kernel (check correctness vs. PyTorch on hardware), profile_kernel (measure execution time and per-engine utilization), and skill_lookup (retrieve NKI optimization patterns). It iterates up to 10 turns — write, compile, fix, verify, profile, optimize.
Hardware-aware reward shaping
Prior work on RL for code generation — CodeRL (Le et al., NeurIPS 2022), PPOCoder (Shojaee et al., 2023), and RLTF (Liu et al., 2023) — uses pass/fail rewards based on compilation and test outcomes. We add two bonuses specific to NeuronCore architecture:
- Engine bonus (+0.5): any single engine utilization exceeds 70%
- Multi-engine bonus (+0.5): Tensor Engine > 30% AND Vector Engine > 30%
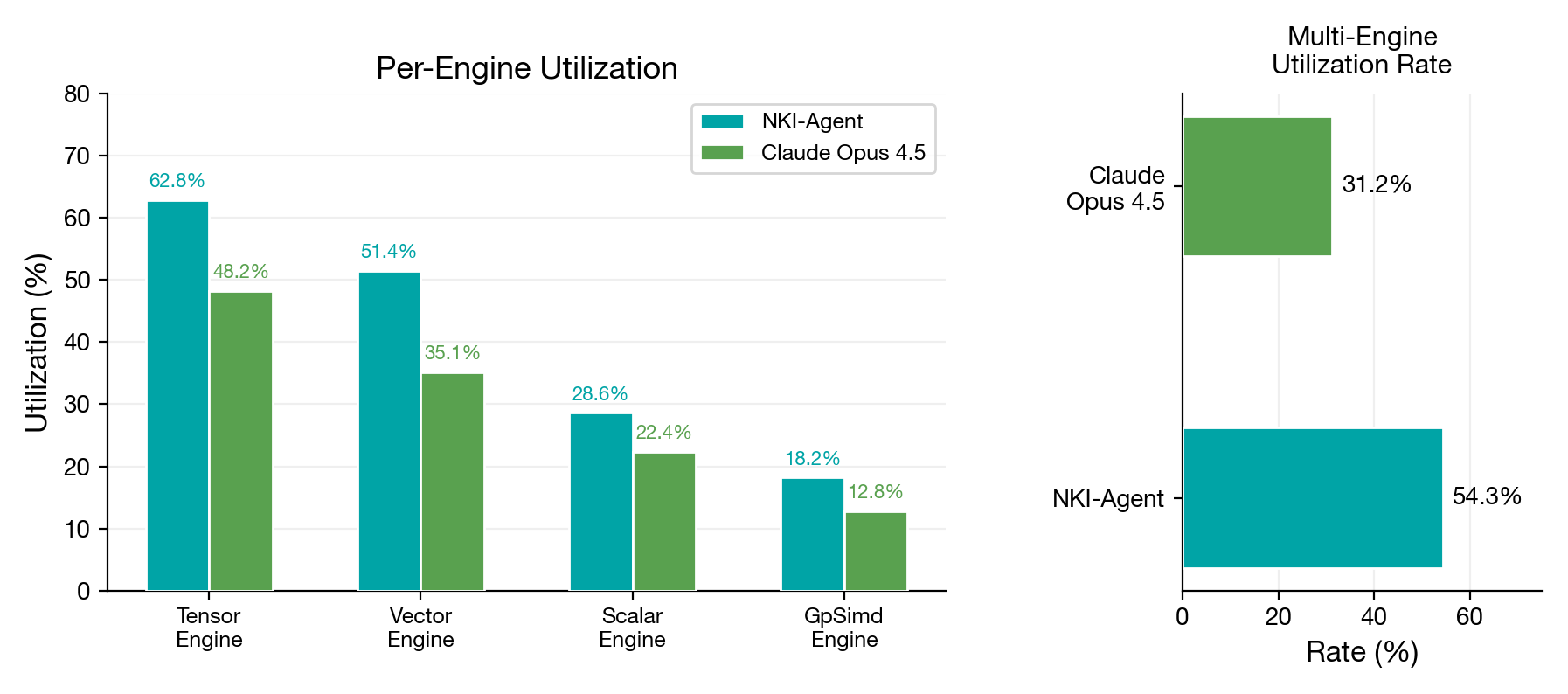
NeuronCores are designed for pipeline parallelism. A kernel using only the Tensor Engine leaves 75% of the chip idle. The multi-engine bonus explicitly rewards distributing work across engines — something Claude Opus 4.5 rarely does unprompted.
We train with Proximal Policy Optimization (Schulman et al., 2017) using asymmetric clipping (epsilon_lo=0.2, epsilon_hi=0.28). The wider upper bound lets the policy explore more aggressively when it discovers promising optimization strategies.
Selecting the right base model with MoE

Qwen3-Coder-30B-A3B is ideal: large total parameter count provides broad code understanding, while low active count (3B) enables fast inference at 7.1 tok/s. LoRA training touches only 26.7M parameters and completes in 47 minutes. The practical takeaway: you don’t need massive compute to beat frontier models on a specialized domain — you need the right reward signal.
Benchmark results on 250 NKI kernel tasks
We evaluate on NKIBench — 250 tasks at three levels: single operations (100), fused operations (100), and full model components (50). Baselines — Claude Opus 4.5, Kimi K2.5, and GLM-4.7 — all use the same agent scaffold with identical tools.
NKI-Agent widens the gap at higher difficulty
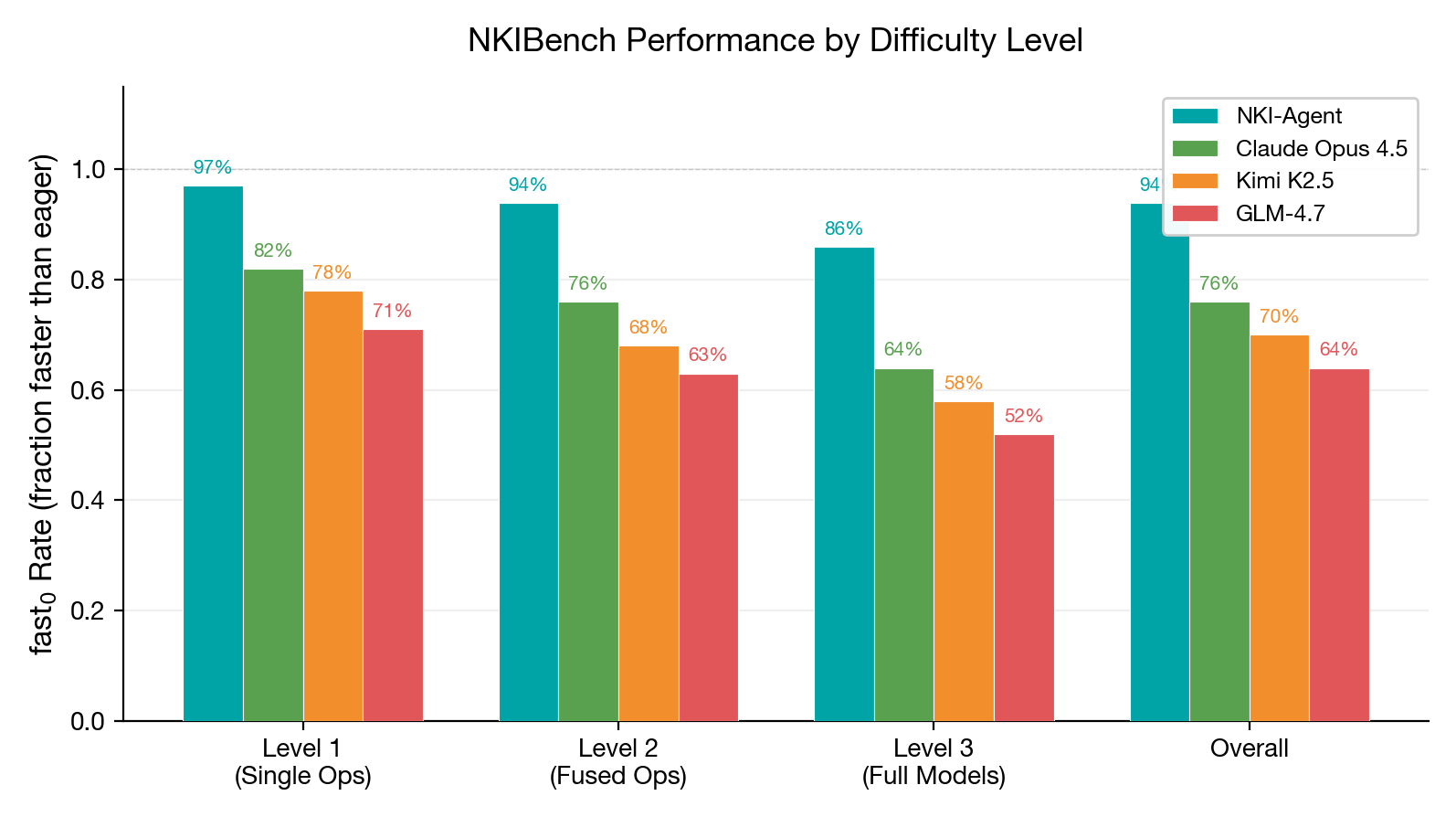
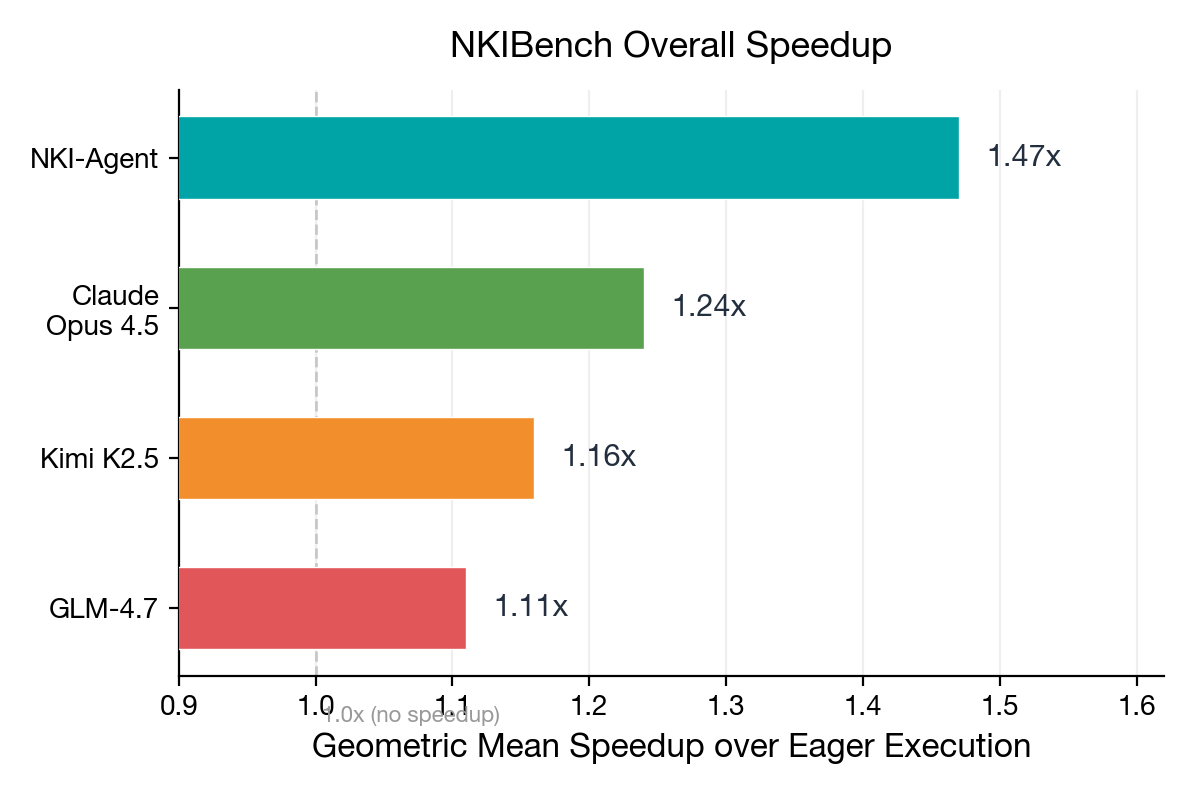
1.47x geometric mean speedup over eager execution
Engine utilization rewards change agent behavior
Ablation: warm starting and engine bonuses matter most
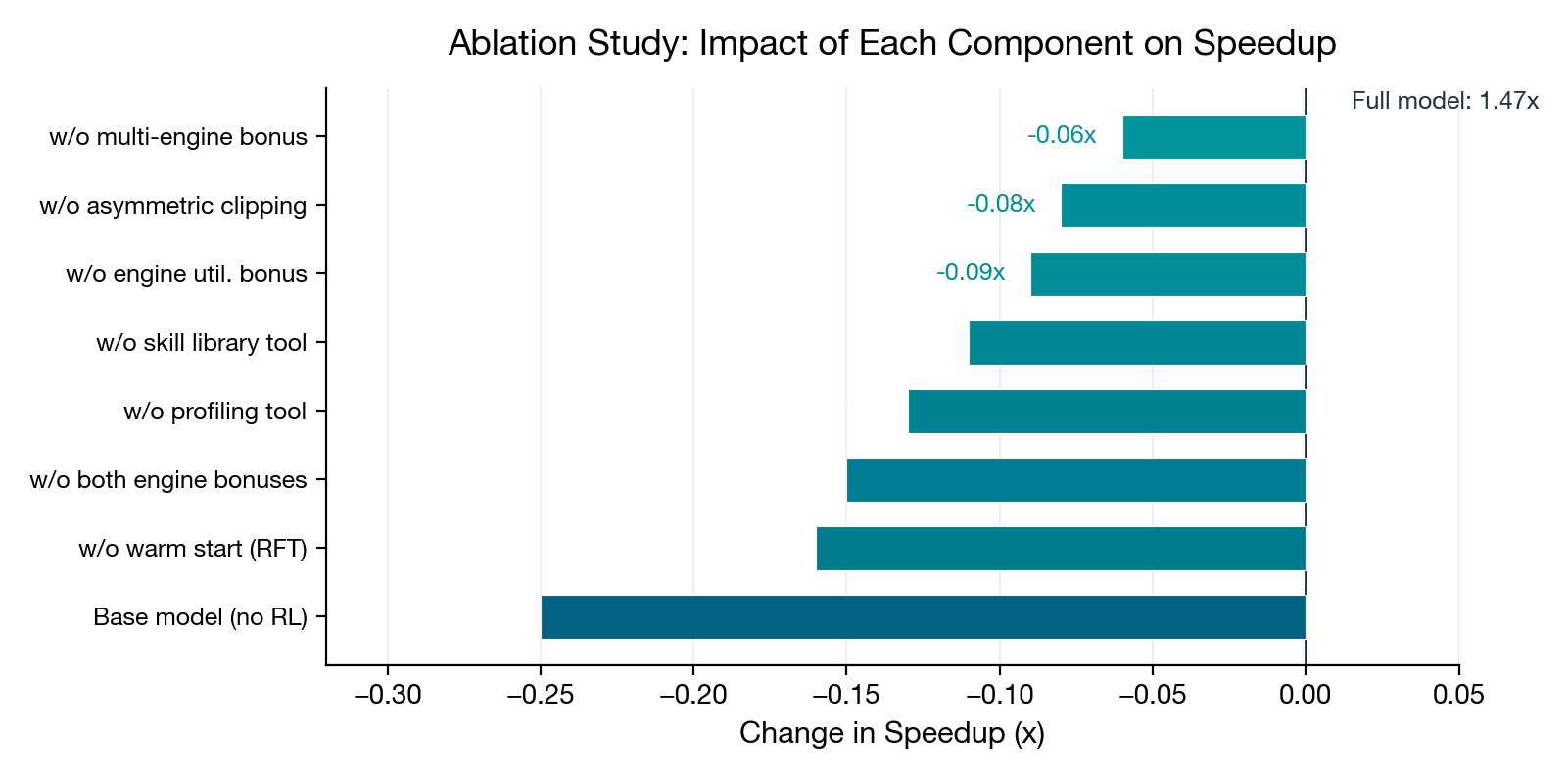
Three findings: (1) Rejection fine-tuning provides the largest single-component effect (–0.16x), confirming that initial policy quality is crucial for stable PPO. (2) Engine bonuses are the second-largest factor (–0.15x), validating that general-purpose code rewards are insufficient for hardware-specific optimization. (3) The profiler (0.13x) and skill library (0.11x) are complementary — one guides optimization direction, the other teaches NKI-specific patterns.
Practical takeaways
For RL-for-code researchers: Hardware-aware reward shaping is high-leverage. Reward the way hardware is used, not just correctness and speed. Asymmetric PPO clipping helps in domains with sparse, multi-modal rewards. MoE models are excellent RL bases — broad knowledge, cheap training.
For kernel generation: Frontier LLMs are surprisingly capable at NKI with tools (Claude Opus 4.5 gets 76% fast rate), but plateau on multi-engine optimization. A compile-verify-profile loop is essential. Warm starting matters more than any single reward component.
For NKI developers: Multi-engine pipelining is the key optimization axis. The 128-element partition dimension is the hardest constraint for all models.
Get started
Replicate and extend these results using the following resources:
- NKI programming guide — core documentation for writing Neuron kernels
- nki-samples — reference kernel implementations (MIT-0)
- Strands Agents — open-source agent framework used in this work (Apache 2.0)
- KernelBench — the GPU kernel benchmark we adapted for NKI
For NKI kernel development, start with an Amazon EC2 Trn1 instance and the AWS Neuron SDK. For RL training, a single g5.48xlarge completes the full pipeline in under an hour for under $200.
Open source coming soon. We are preparing to release the full Kernel Forge codebase, NKIBench benchmark, and trained model weights. Stay tuned.
References
- CUDA-Agent — Wu et al., Agentic Reinforcement Learning for CUDA Kernel Generation, arXiv:2602.24286, 2026. The direct inspiration for this work; we adapt the agentic RL approach from CUDA to NKI.
- KernelBench — Ouyang et al., Can LLMs Write GPU Kernels?, arXiv:2502.10517, 2025. Benchmark and task formulation we adapted for NKI.
- PPO — Schulman et al., Proximal Policy Optimization Algorithms, arXiv:1707.06347, 2017. Core RL algorithm; we extend with asymmetric clipping.
- CodeRL — Le et al., Mastering Code Generation through Pretrained Models and Deep Reinforcement Learning, NeurIPS 2022. Pioneered RL for code generation with execution feedback.
- PPOCoder — Shojaee et al., Execution-based Code Generation using Deep Reinforcement Learning, arXiv:2301.13816, 2023.
- RLTF — Liu et al., Reinforcement Learning from Unit Test Feedback, arXiv:2307.04349, 2023.
- SWE-agent — Yang et al., Agent-Computer Interfaces Enable Automated Software Engineering, arXiv:2405.15793, 2024. Influenced our tool-using agent design.
- Toolformer — Schick et al., Language Models Can Teach Themselves to Use Tools, NeurIPS 2023.
- Qwen3-Coder — Qwen Team, Qwen3-Coder-30B-A3B-Instruct, 2025. Base model for Kernel Forge.
- Codex — Chen et al., Evaluating Large Language Models Trained on Code, arXiv:2107.03374, 2021.
- AlphaCode — Li et al., Competition-Level Code Generation with AlphaCode, Science 378(6624), 2022.
Enjoy Reading This Article?
Here are some more articles you might like to read next: