Five Rules for Multi-Agent Coding Teams — Derived From 27 Controlled Experiments
- What the data looks like
- Rule 1: Default to 3–5 agents
- Rule 2: One shared project directory, per-agent write scopes
- Rule 3: Nightly integration tests, with failure injection
- Rule 4: One dedicated DevOps agent owns deployment
- Rule 5: N≥2 runs, and report variance
- Does the software actually work? (The circular-metric problem)
- N=3 reproducibility at 10-day horizon
- Five-pillar evaluation
- What to do with this
- References
Disclaimer: The views and opinions expressed in this post are my own and do not represent those of my employer.
Most multi-agent coding demos are indistinguishable from each other. A team of LLMs builds something. Screenshots get posted. Nobody tries to deploy it, and if they did, it wouldn’t run. The field doesn’t lack demos. It lacks operating rules — the load-bearing decisions that separate teams that produce deployable software from teams that produce interesting-looking artifacts.
This post presents five such rules, derived from 27 controlled experiments across two domains and two model generations. A one-page summary of the rules lives at AGENTS.md. This post gives the reasoning, the evidence, and the limitations behind them.
The five rules:
- Default to 3–5 agents.
- One shared project directory with per-agent write scopes.
- Nightly integration tests. Inject failures into tomorrow’s prompt.
- One dedicated DevOps agent owns the deployment artifacts.
- N≥2 runs per configuration, or you’re reporting noise.
If you only read this far: start there. The rest of the post answers why each rule is load-bearing and what happened when I violated it.
What the data looks like
I built AgentCorp, a framework that runs N LLM agents through a simulated 10-day sprint against a project specification, with a shared repo, per-agent scopes, and a nightly integration suite. Model: Claude Opus 4.6 for planner and judge, Claude Sonnet 4.6 for workers. Opus 4.7 runs exist but are preliminary (N=1) and excluded from the main results. The complete run artifacts will be open-sourced (coming soon).
The target project: a Physical AI factory. Digital twin with OEE monitoring, CV-based defect detection on SageMaker, predictive maintenance with time-series anomaly detection, AGV routing with constraint solvers, RL-trained robotic assembly on HyperPod, edge deployment via Greengrass, and a governance layer (AgentCore) tying it all together. Real AWS service calls, mock physical interfaces, 14 user stories, 43 story points.
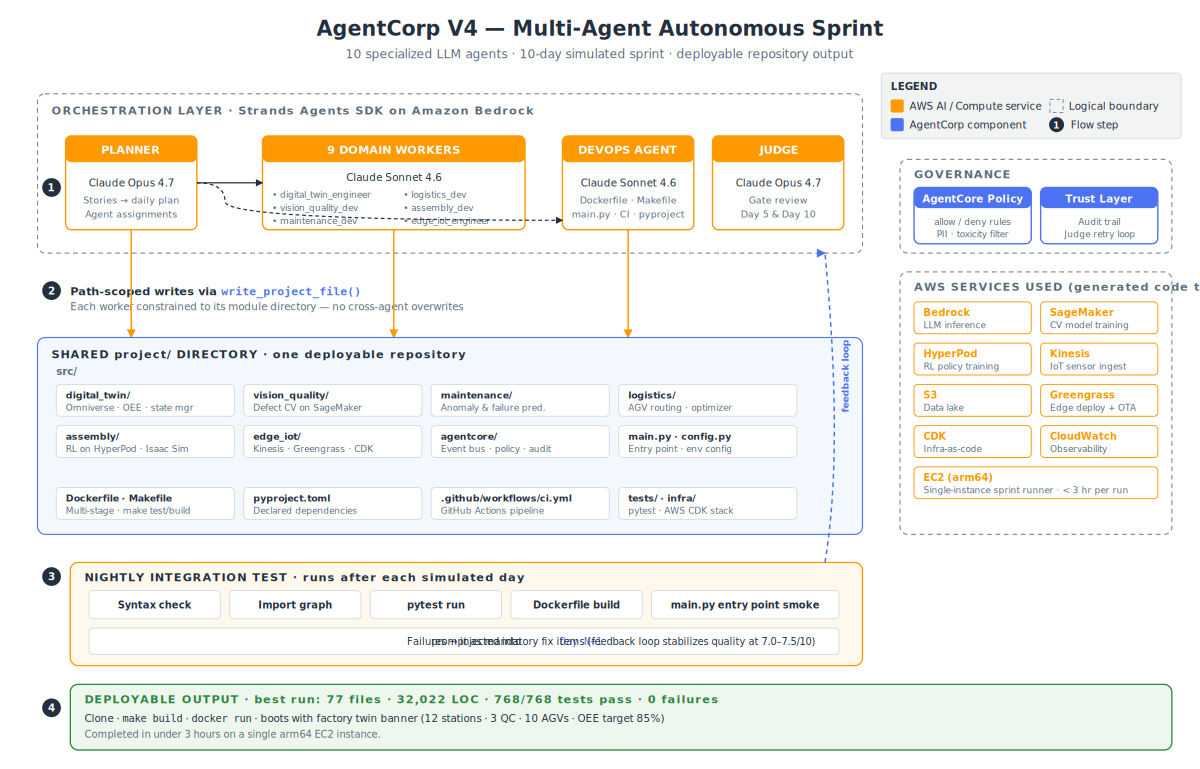
What I’m claiming, and what I’m not. I’m claiming the five rules above are necessary conditions for producing a deployable repository from an LLM team over a multi-day horizon. I’m not claiming they’re sufficient, and I’m not claiming the agents’ own test suites prove the resulting software works — that’s a real limitation and the last section addresses it directly.
Rule 1: Default to 3–5 agents
The trap. More agents is the obvious first move. More specialization, more parallelism, more throughput. It’s how human teams scale.
What I found. Across 18 controlled baseline runs (3 complexities × 2 team sizes × 3 repeats, LLM-judged artifact quality), 5-agent teams outperformed 10-agent teams on every complexity level and every repeat. The verified average across 1-week and 2-week sprints:
| Sprint | 5-agent (N=3) | 10-agent (N=3) | Δ |
|---|---|---|---|
| 1-week (todo app) | 7.82 | 6.50 | +20.3% |
| 2-week (knowledge base) | 7.38 | 6.79 | +8.7% |
| Weighted avg | 7.60 | 6.64 | +14.4% |
4-week (project-management SaaS) runs completed but were under-evaluated; direction held, precise magnitude pending rerun.
Caveat on the measurement. These are LLM-judged process scores — artifact clarity, structure, documentation — scored by Claude Sonnet 4.6 at temperature 0.0. The low variance across reruns (pillar SD = 0.05) reflects both output stability and judge determinism at temp-0; the two are entangled in this setup. The scores are a directional signal, not a definitive one. The stronger evidence is Rule 4’s result below, where 5-agent teams produce complete deployment stacks and 10-agent teams were the configurations that burned the most tokens fighting themselves.
The mechanism. A single agent holds the full project in its context window. Every split compresses that understanding. I call this the Context Consolidation Paradox: splitting a project across N agents strictly decreases information coherence, and you only recover it through coordination machinery that itself costs signal. This is Amdahl’s Law applied to agent teams — when serial work (architecture, integration, review) dominates, adding agents adds overhead without proportional gain.
What didn’t work. I tried four literature-recommended coordination patterns on the 10-agent teams:
- Coordinator synthesis — the planner writes a detailed spec before delegating
- Shared scratchpad — persistent file for durable decisions
- Self-contained prompts — every worker prompt carries full context
- Skeptical memory — agents verify memory against code before acting
Every pattern reduced the mean quality score. All four reduced variance by ~79%, so they made 10-agent teams more consistent — consistently worse than 5-agent teams. Adding coordination machinery to a team that’s already fighting context-window limits compounds the problem.
Rule: start at 3 agents. Move to 5 when specialization obviously helps. Don’t go higher unless your measurements demand it.
Rule 2: One shared project directory, per-agent write scopes
The trap. Give each agent its own output folder. Merge at the end. “Like feature branches.”
What I found. Every configuration that used per-day or per-agent output directories produced zero lines of deployable code. Not fewer — zero. The project/ directory stayed empty across 30+ early runs. Each agent produced its artifacts in isolation; nothing connected; nothing shipped.
Every configuration that used a shared project/ directory with path-scoped writes produced 18K–35K LOC of working software.
The mechanism. Agents write to where they think code belongs. Without a shared physical tree, they can’t see each other’s work even if they read each other’s outputs. A file exists in one place; the rest is citation. Shared directory turns citation into dependency — agents read and import each other’s code as they build. Per-agent scoping prevents them from overwriting each other while doing it.
Concrete: one src/ tree. Billing agent writes only to src/billing/. Auth agent writes only to src/auth/. Shared contracts live in src/common/ owned by the planner. git log --name-only should show each file touched by exactly one agent.
Rule: one shared repo from day one. Enforce write scopes at the tool layer, not by prompt convention.
Rule 3: Nightly integration tests, with failure injection
The trap. Tests at the end. Milestones every few days. “Agents can self-correct.”
What I found. Without nightly tests, per-day quality in multi-day sprints swung from 4.0 to 9.0. Agents compound mistakes silently — day 3’s broken import becomes day 7’s architectural tangle. With nightly tests, per-day quality held 7.0 to 10.0 across all runs.
The minimum nightly suite that worked:
- Syntax check — every
.pyparses - Import check — cross-module imports resolve
-
pytestrun — all discovered tests pass - Dockerfile check — valid structure, entry point exists
- Hardcoded-values check — no account IDs, no pinned regions
Day N+1’s prompt begins with: “These tests failed yesterday. Fix them first before writing new code.”
Verify the harness itself. In two of my N=3 runs, a path bug silently made pytest collect zero items for the entire 10-day sprint. The agents received no real test feedback for ten simulated days and still produced 92% and 95% pass rates — which is impressive and also a harness bug that masked the problem for weeks. If your feedback loop can fail quietly, assume it will. Add a liveness check.
Rule: build the feedback loop on day one, verify it before you trust it, and injection-feed failures into the next day’s prompt.
Rule 4: One dedicated DevOps agent owns deployment
The trap. “The senior engineer will handle the Dockerfile.” (Spoiler: no senior engineer.)
What I found. This is the starkest result in the entire dataset. Across 30+ experiments without a dedicated DevOps role, agents produced zero deployment artifacts. No Dockerfile. No Makefile. No main.py. No CI. Domain agents write domain code; without explicit ownership, nobody writes glue.
With a dedicated DevOps agent in every subsequent run: Dockerfile, Makefile, src/main.py, pyproject.toml, and .github/workflows/ci.yml appeared in every single run. 100% hit rate.
The DevOps agent’s scope:
-
Dockerfile,docker-compose.yml -
Makefilewithtest,lint,build,runtargets -
src/main.py— entry point that wires all modules -
pyproject.toml— dependencies, pytest config .github/workflows/ci.yml
No other agent touches these. DevOps reads the project structure each day and builds the glue.
Rule: deployment artifacts are not a shared responsibility. Give them a single owner, or they don’t get written.
Rule 5: N≥2 runs, and report variance
The trap. Publish the best run. Call it a demo.
What I found. Two runs of an identical 10-agent configuration produced: Run 1, 55 test errors; Run 2, zero. If I’d published Run 2 only, the configuration would look flawless. If I’d published Run 1 only, the configuration would look broken. Both runs were real. Both were the same config.
For the 5-agent configuration at N=3, pass rates landed at 92%, 99%, 95%. Consistent, but the spread is still 7 percentage points on identical inputs.
Rule: run every configuration at least twice. Pre-register what “success” means before you see results. Report mean and variance. If runs disagree materially, that is the finding.
Does the software actually work? (The circular-metric problem)
Here’s the concern I have to address directly. The agents wrote the tests. The tests pass. Reporting 92–99% pass rates on self-generated test suites is the multi-agent equivalent of a student grading their own exam.
I can’t fully escape this with the current harness. I can measure things external to the agents’ test suites:
What’s externally verifiable in the generated repos today:
-
docker buildsucceeds on every N=3 run. The image has an entry point. It starts. -
main.pyimports all modules without errors. No circular imports, no missing symbols across 67–88 Python files per run. - The CDK stack synthesizes. The infrastructure template is valid CloudFormation.
- The Dockerfile is multi-stage, follows standard patterns, sets
WORKDIR, exposes health ports. - Cross-module event chains (
defect_detected → maintenance_check → agv_reroute → assembly_reschedule → digital_twin_update) are wired through EventBridge with realboto3calls.
What’s not externally verifiable yet:
- Whether the business logic produces correct output on held-out inputs. The agents’ tests check their own expectations; they don’t check against a ground truth I provided.
- Functional coverage — what behavior the tests actually exercise — is unmeasured.
- Whether the CDK stack would deploy cleanly to a real account (it synthesizes; I haven’t paid to deploy it).
The honest version: the 92–99% pass rates show the agents’ output is self-consistent at high density. They’re not proof of correctness. The deployment artifacts, the import graph, and the CDK synthesis are external checks — they fail or pass for reasons outside the agents’ control. Those are the numbers to trust most.
The next work item is adding a held-out test suite I write (not the agents) for a subset of domain modules, plus functional coverage analysis. That closes the gap between “tests pass” and “the system works.” I’ll publish that as a follow-up when the data exists.
N=3 reproducibility at 10-day horizon
Supporting evidence for the rules above. Three identical runs of the 5-agent configuration on the Physical AI sprint:
| Metric | Run 1 | Run 2 | Run 3 | Mean ± SD |
|---|---|---|---|---|
| Days completed | 10/10 | 10/10 | 10/10 | — |
| Stories / points | 14/14, 43/43 | 14/14, 43/43 | 14/14, 43/43 | — |
Python files in project/ | 67 | 84 | 88 | 80 ± 11 |
| Lines of code | 28,516 | 30,381 | 35,073 | 31,323 ± 3,399 |
| 5-pillar avg | 6.88 | 6.94 | 6.97 | 6.93 ± 0.05 |
| pytest pass rate | 92.0% | 99.1% | 95.3% | — |
| Deployment artifacts present | all | all | all | — |
docker build succeeds | yes | yes | yes | — |
All three completed under three hours on a single arm64 EC2 instance (61 GB, 8 vCPU). Pillar score SD = 0.05 — partly output stability, partly the temp-0 judge returning similar scores on similar artifacts; I can’t fully disentangle these in the current harness. For calibration, the 6.93 mean sits in the upper-middle of the score range this framework produces; the best observed single-run score across the full experiment set was 7.27. The 5-pillar average is capped implicitly by the Outcome pillar, which is limited by how much of the work is verifiable — the next section explains why.
These are identical-input reruns — they establish bounded LLM sampling variance on a fixed task, not cross-task generalization.
Post-hoc fixes, disclosed: pytest timeout config added to all runs to handle hanging subprocess tests; one 1-line dataclass fix in Run 3 (description: str → description: str = "") without which zero tests collect; one test-code fix in Run 3 to skip CDK synthesis tests that spawn unkillable Java subprocesses. Runs 1 and 2 had no source-code changes. All fixes are documented and will be visible in the commit history of the upcoming open-source release.
A note on cost. I don’t have precise per-run cost numbers to publish — the token counter in the sprint harness was wired for cost logging but never instrumented end-to-end, so every cost_usd field in the run artifacts reports 0.0. Wall-clock per run was ~3 hours on a single EC2 instance. A 5-agent team with an Opus planner + judge and Sonnet workers across a 10-day sprint with ~1,200 tool calls per run lands in the high-single-digit to low-double-digit USD range at current Bedrock pricing, based on my back-of-envelope sampling — but I won’t claim a number I didn’t measure. Adding proper token accounting is on the roadmap.
Five-pillar evaluation
The rubric that exposed the issue. An earlier configuration scored 9.3/10 on process metrics — clean code, strong docs, excellent coordination. Then I checked the tests: 44% pass rate. Beautiful, disconnected code.
That forced a rethink. A single overall score hides too much. I needed a framework that separates how well the agents follow instructions from whether the output actually works. The 5-pillar framework I built after that:
| Pillar | What it measures | Why it matters |
|---|---|---|
| LLM Quality | Instruction-following, code structure, documentation quality, safety compliance | Catches agents that write plausible but wrong code — hallucinated APIs, ignored constraints, unsafe patterns |
| Memory | Cross-day context retention, decision consistency, scratchpad usage | A 10-day sprint is useless if agents forget day 3’s architecture decisions by day 7. This pillar catches context drift |
| Tools | Tool call success rate, appropriate tool selection, error recovery | Agents that call the wrong tool or fail silently waste entire sprint days. Measures whether the agent-tool interface is reliable |
| Environment | AWS service naming accuracy, IAM policy correctness, resource configuration, guardrails | The difference between sagemaker:CreateEndpoint and a hallucinated API. Wrong service names mean nothing deploys |
| Outcome | Test pass rate, deployment readiness (Docker builds, entry point works), story completion, integration test results | The only pillar that answers: does it run? Everything else is process. This is the product |
How scoring works. Claude Sonnet 4.6 at temperature 0.0 evaluates each pillar on a 1–10 scale against the project specification and sprint artifacts. The low variance across reruns (SD = 0.05) reflects both genuine output stability and judge determinism at temp-0 — the two are entangled in this setup. The scores are a directional signal, not ground truth.
The key insight: the first four pillars can all score 9+ while Outcome scores 4. That’s exactly what happened in early runs. The Outcome pillar is the only one that separates “passes a review” from “runs in production”. Any agent evaluation without an Outcome pillar is measuring politeness, not capability.
What to do with this
If you’re building a multi-agent coding system:
- Adopt the five rules before tuning anything else. They cost nothing to implement and they dominate the impact of any model choice.
- Build the feedback loop first, and verify it works. Silent failures in your evaluation harness will mask problems for weeks.
- Measure externally. Ship to Docker. Run
main.py. Synthesize the CDK stack. Don’t trust the agents’ own tests as your primary signal. - Report variance. If you have N=1, you have a story, not a result.
The one-page rules summary is open-source at github.com/JunjieTang-D1/agents-md (MIT). The experimental framework and raw run artifacts will follow — stay tuned.
AgentCorp uses Amazon Bedrock (Claude Opus 4.6 for planner and judge, Claude Sonnet 4.6 for workers), Strands Agents SDK, and OpenTelemetry for observability. All experiments ran on a single arm64 EC2 instance (61 GB RAM, 8 vCPU).
References
- Jinxin, L., et al. (2026). Multi-Agent Teams Hold Experts Back: Integrative Compromise in LLM Collaboration. arXiv:2602.01011. https://arxiv.org/abs/2602.01011
- Zhang, Y., Liu, T., Chen, X., Wang, H., & Kumar, S. (2026). Amdahl’s Law for Agent Teams: Characterizing Parallelization Limits in Multi-Agent Systems. arXiv:2603.12229. Princeton · MIT · Cambridge · NYU. https://arxiv.org/abs/2603.12229
- Benkovich, et al. (2026). Agyn: Team-Based Autonomous Software Engineering. arXiv:2602.01465. https://arxiv.org/abs/2602.01465
- Zechner, et al. (2026). TheBotCompany: Self-Organizing Multi-Agent Systems for Continuous Software Development. arXiv:2603.25928. https://arxiv.org/abs/2603.25928
- Qian, C., et al. (2024). ChatDev: Communicative Agents for Software Development. ACL 2024. arXiv:2307.07924.
- Hong, S., et al. (2024). MetaGPT: Meta Programming for a Multi-Agent Collaborative Framework. ICLR 2024. arXiv:2308.00352.
- Jiménez, C. E., et al. (2023). SWE-bench. arXiv:2310.06770.
- Amdahl, G. M. (1967). Validity of the single processor approach to achieving large scale computing capabilities. AFIPS SJCC.
- Brooks, F. P. (1975). The Mythical Man-Month. Addison-Wesley.
- Rajasekaran, P. (2026). Harness Design for Long-Running Application Development. Anthropic Engineering. https://www.anthropic.com/engineering/harness-design-long-running-apps
- AgentCorp source code and experimental data — releasing publicly soon.
Like this post? Click to applaud!
Enjoy Reading This Article?
Here are some more articles you might like to read next: