Running Graph Neural Networks on AWS Trainium Without PyTorch Geometric
Disclaimer: The views and opinions expressed in this post are my own and do not represent those of my employer.
The GNN community has a hidden dependency problem. PyTorch Geometric - the library underneath virtually every graph neural network in production, with 23,000+ GitHub stars - hardcodes CUDA scatter kernels into its critical path. If your accelerator doesn’t support CUDA, your GNN doesn’t run.
This isn’t a minor compatibility issue. It means every GNN workload - autonomous driving scene understanding, drug discovery, recommendation systems - is locked to one hardware vendor. PyG issue #1584 has been open since 2020. Five years, no fix.
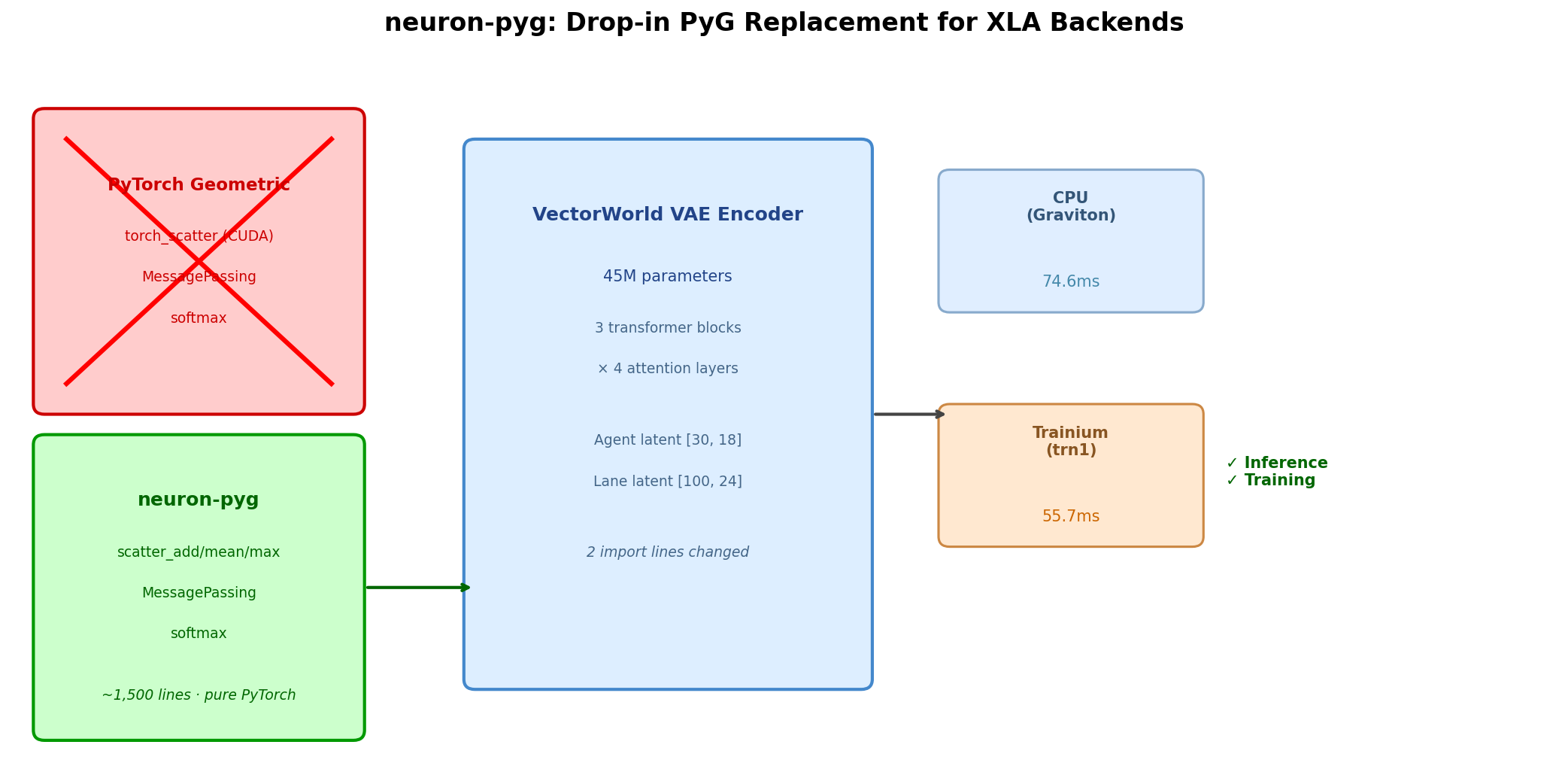
We decided to fix it ourselves. neuron-pyg is ~1,500 lines of pure PyTorch that replaces PyG’s core operations with XLA-compatible implementations. We validated it by running VectorWorld’s full 45M-parameter VAE encoder on Trainium with pretrained weights - numerically equivalent outputs to the original PyG implementation.
The three operations that break everything
PyTorch Geometric’s XLA incompatibility comes from three categories of operations:
- CUDA-specific scatter kernels.
torch_scatterprovidesscatter_add,scatter_mean,scatter_maxas custom CUDA extensions. No XLA lowering exists. - Dynamic shapes from sparse operations. GNN neighborhoods are variable-size. PyG handles this with dynamic indexing that XLA’s ahead-of-time compiler can’t trace.
- Python control flow in critical paths. A naive
scatter_maxiterates with Pythonfor/if- breaking XLA graph tracing.
neuron-pyg replaces each with XLA-compatible alternatives using scatter_add_(), vectorized one-hot masking for scatter_max, and gradient-safe softmax with arithmetic clamping.
Numerically equivalent outputs
We loaded identical weights into both the original PyG-based VectorWorld layers and their neuron-pyg replacements, fed identical inputs, and compared outputs. Across four core layers - AttentionLayerDiT, AttentionLayer, EdgeFeatureUpdate, and GlobalContextFusion - all outputs matched within tolerance (atol=1e-5, rtol=1e-4). The underlying scatter and softmax operations produce numerically equivalent results because they implement the same mathematical operations - just without the CUDA dispatch layer.
Validation: VectorWorld’s VAE encoder
VectorWorld (Jiang et al., 2026) is a streaming world model for autonomous driving that uses PyG extensively. Its VAE encoder exercises every neuron-pyg primitive: 45M parameters, 3 transformer blocks × 4 attention layers, lane-to-lane self-attention, agent-to-agent self-attention, cross-attention, and edge feature updates.
The migration: 2 import lines changed in the layers file, with the underlying scatter and softmax implementations rewritten for XLA. No model architecture modifications. Pretrained checkpoint loads directly.
Inference with pretrained weights
All 424 checkpoint keys loaded successfully. The encoder produces correctly shaped outputs (agent [30,18], lane [100,24], cond_dis [1,101]) with no NaN or Inf values, at a median latency of 55.7ms on trn1.2xlarge. First-run XLA compilation takes ~54s across 30+ HLO graphs, but subsequent runs use cached NEFFs and start in under a millisecond.
Training convergence
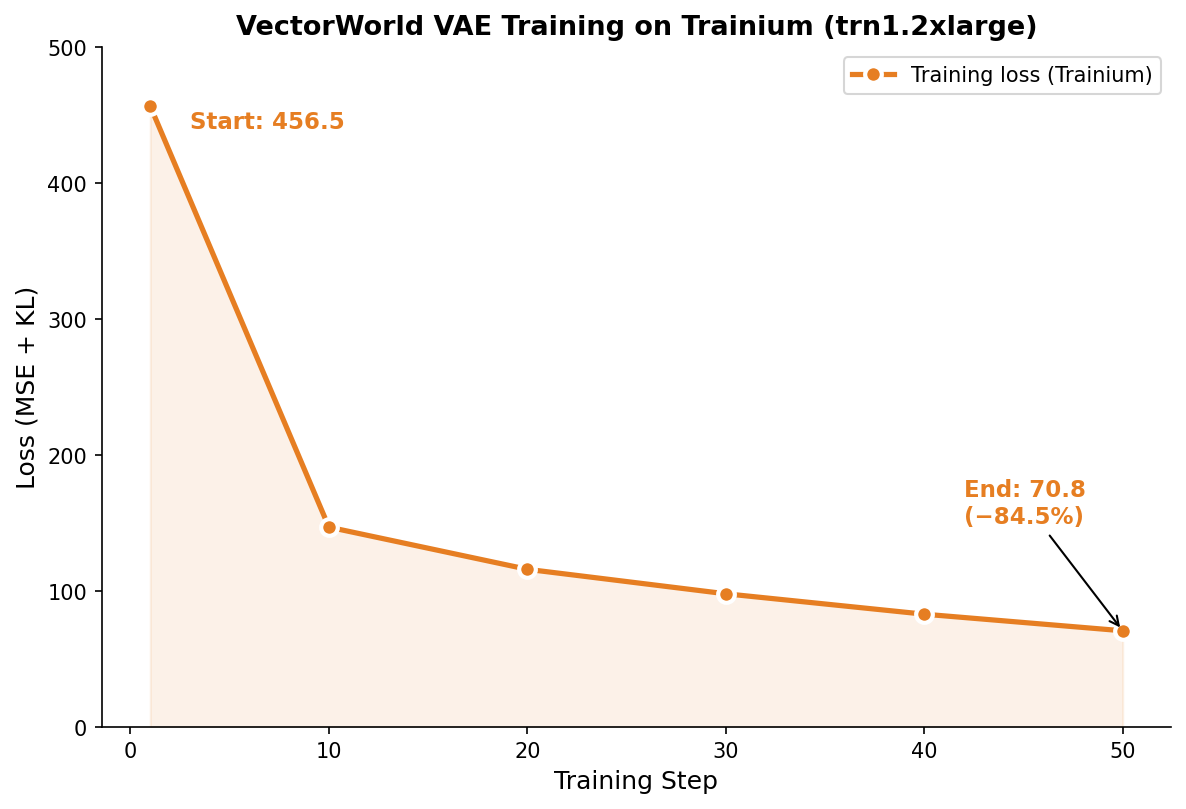
Training loss drops from 456.5 to 70.9 (−84.5%) over 50 steps with a median step time of 178.6ms. This validates that gradients flow correctly through all scatter operations and the optimizer updates weights as expected. Full training to convergence on real Waymo data is future work.
XLA compilation: a one-time cost
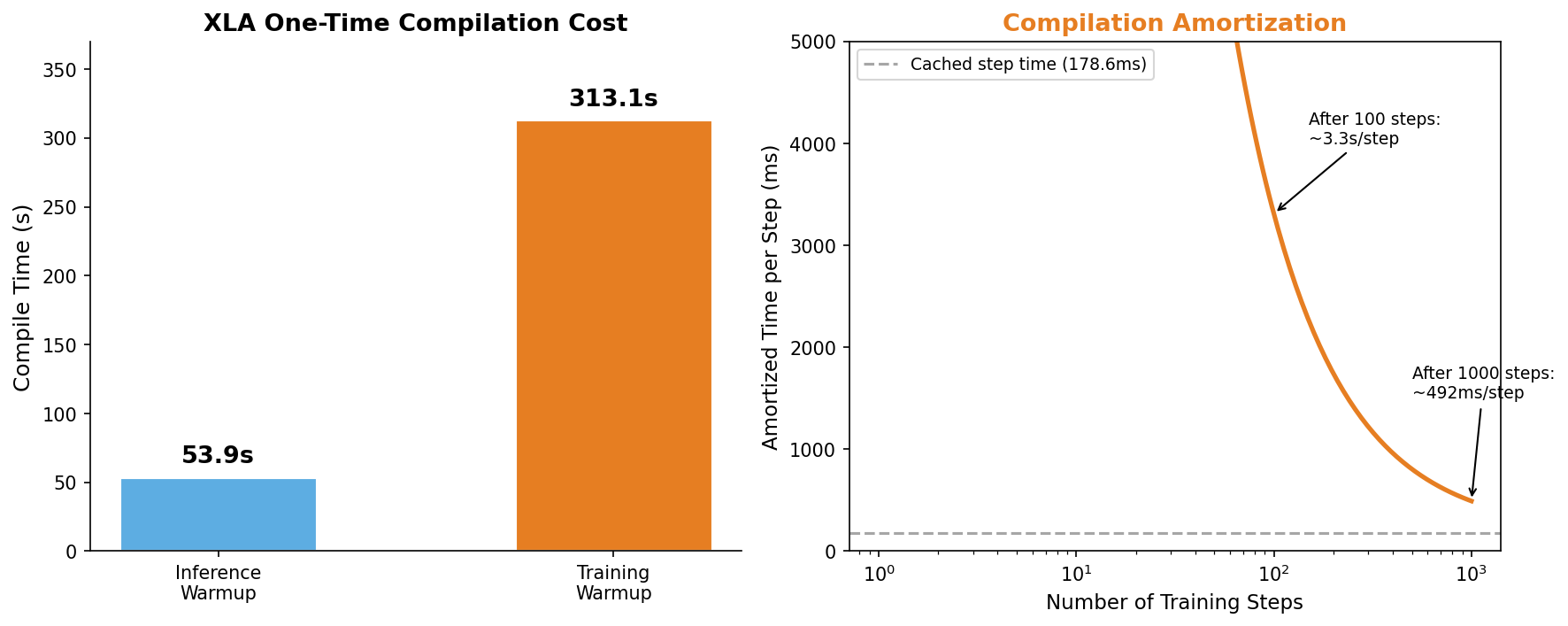
The Neuron compiler persists compiled NEFFs to disk. On re-runs with the same model and shapes, all graphs load from cache - reducing warmup from minutes to milliseconds. Compile once, run thousands of times.
Limitations
- Memory overhead. The vectorized
scatter_maxcreates intermediate tensors that grow with graph size. For graphs with >100K edges, a custom NKI kernel would be more efficient. - Single-device only. Not tested with
torch_xla.distributed. Multi-NeuronCore training is future work. - No real Waymo data. We validated with synthetic scenes matching VectorWorld’s format and with pretrained weights. Full validation on the licensed Waymo Open Dataset is future work.
What’s next
- PyG upstream PR: Submit XLA-compatible backends to PyTorch Geometric, building on issue #1584
- NKI scatter kernel: Custom Neuron kernel for
scatter_maxto optimize memory access patterns - Trainium2 validation: trn2 should improve both compile and runtime
- Additional model validations: QCNet, DSVT, PointPillars
All benchmarks: trn1.2xlarge (Neuron SDK 2.9, neuronx-cc 2.23). VectorWorld checkpoint: Jck1998/vectorworld (Waymo VAE). Code and equivalence tests: neuron-pyg. 67 unit tests, Apache 2.0 license.
Like this post? Click to applaud!
Enjoy Reading This Article?
Here are some more articles you might like to read next: